This post was originally written in Chinese and translated to English by Claude Opus 4.6. The original version is here.
I previously studied OpenClaw's memory system and Supermemory's architecture, one being a coding agent's local memory and the other memory-as-a-service. But when it comes to "AI memory," the first system most people encounter is probably ChatGPT.
Based on OpenAI's documentation, reverse engineering by multiple researchers, and my own verification, ChatGPT's memory is most likely a hybrid system: one layer is a pre-computed user profile injected into the context at the start of each conversation; the other is on-demand retrieval that searches past chats when a question might depend on conversation history.
The former lets it "know you" from the first message. The latter lets it find more specific old conversations. But this also means every response you see may have already been shaped by an invisible, not fully editable user dossier.
Layer 1: Pre-computed User Information
OpenAI's own documentation says Memory has two layers: "Saved Memories" (things you asked it to remember, or facts ChatGPT deemed worth saving) and "Reference Chat History" (preferences and interests the system extracted from past conversations). But the official docs don't share many details about how these are stored or used.
Through prompt probing (getting ChatGPT to dump the structure of its own system prompt), you can see what's actually in ChatGPT's context. Every time you send a message, ChatGPT's context window contains, beyond system instructions and the current conversation, a large block of information about you:
System Instructions (behavioral rules, tool definitions, safety policies, etc.)
---
Session Metadata (temporary session info)
Model Editable Context (your explicit memories, i.e. Saved Memories)
User Knowledge Memories (AI-generated user profile)
Topic Highlights (long-term topic summaries)
Recent Conversations (recent conversation summaries)
Interaction Metadata (usage metadata)
---
Personal Context Tooling (on-demand retrieval tools)
---
Current conversation messages
The message you just sentThat large middle block is the so-called "user information." Let's go through each one.
Session Metadata
Temporary session information injected when a session starts and discarded when it ends. Contents include your device type, browser, approximate geographic location, timezone, subscription tier, screen size, whether dark mode is on, and so on. Not the core of memory, but it lets ChatGPT adjust responses based on your current environment (for instance, knowing you're on a phone, it might avoid pasting a huge block of code).
Saved Memories (Model Editable Context)
This is the part you can see under Settings > Personalization > Manage memories. In the system prompt, it's called "Model Editable Context." The format is a timestamped list of short facts, like this:
MODEL EDITABLE CONTEXT
1. [2026-01-15]. User is a software engineer based in the Bay Area.
2. [2026-02-03]. User prefers concise answers, dislikes verbose explanations.
3. [2026-03-10]. User is building a personal finance app with React and TypeScript.
4. [2026-03-22]. User is vegetarian.Here's a screenshot of my own ChatGPT account's Saved Memories:
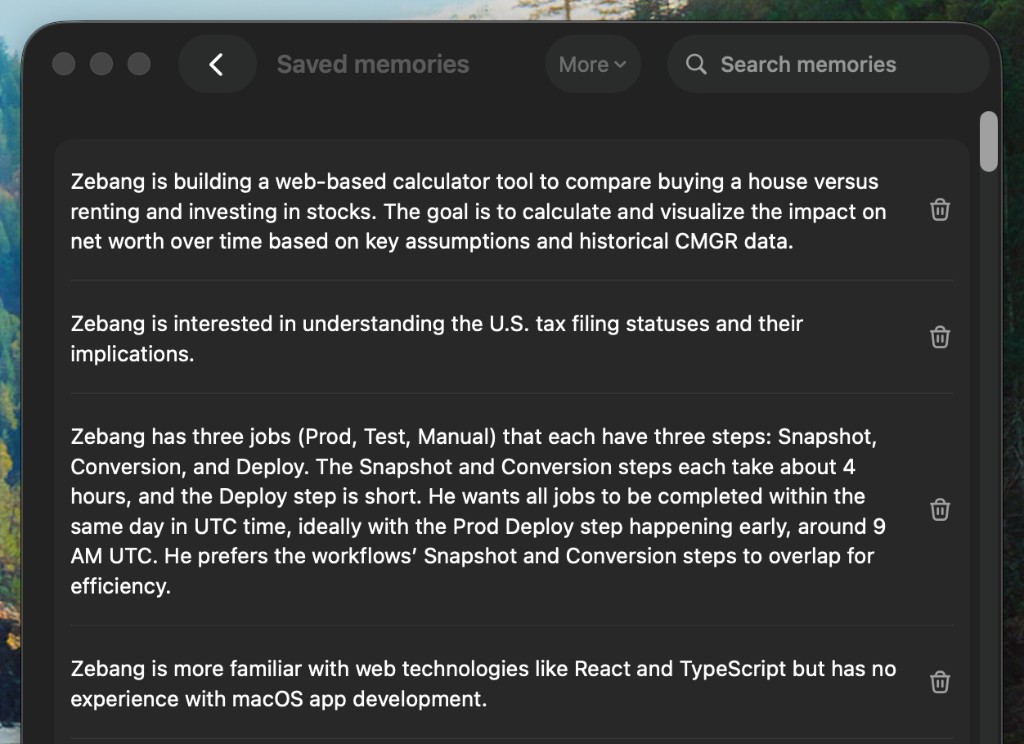
My Saved Memories are organized by category (personal background, career history, projects, tech stack, preferences, recent activity, etc.), totaling about 110 entries.
User Knowledge Memories
The system automatically distills a dense profile from your hundreds of conversations, roughly a few paragraphs to a dozen or so long summaries. These profiles aren't visible in Settings, and users can't directly edit them. The content looks something like this:
HELPFUL USER INSIGHTS
1. User is a software engineer who transitioned from consulting.
Has worked at large tech companies. Frequently discusses
system design, API patterns, and performance optimization.
Confidence=high
2. User is interested in personal finance and quantitative decision-making.
Has built tools to analyze rent-vs-buy decisions and tracks expenses
methodically.
Confidence=high
...Information density is high. Your career background, technical preferences, personal interests, life habits are all in there.
Topic Highlights
High-level topic summaries extracted from your past conversations, used to maintain continuity in new conversations. Usually a few to a dozen entries:
NOTABLE PAST CONVERSATION TOPIC HIGHLIGHTS
1. From early 2026, the user has been actively exploring AI agent memory
systems, including OpenClaw, Supermemory, and various RAG architectures.
The user reads source code and writes technical analysis blog posts
about these systems. Confidence=highRecent Conversations
Summaries of roughly 40 recent conversations. The format is timestamp + title + all your messages, separated by ||||.
RECENT CONVERSATION CONTENT
1. 0427T22:30 ChatGPT memory research:||||帮我研究一下 ChatGPT 的记忆机制||||那在运行时会进行搜索吗?
2. 0427T14:05 TypeScript generics:||||how do I constrain a generic type to have a specific method?
3. 0426T20:12 Dinner ideas:||||I have tofu, mushrooms and rice noodles, what can I make?
...Interaction Metadata
Unlike Session Metadata, this section is persistent behavioral statistics that survive across sessions:
USER INTERACTION METADATA
1. User is currently in United States.
2. User is currently using ChatGPT in a web browser on a desktop.
3. User's account is 80 weeks old.
4. User is currently on a ChatGPT Plus plan.
5. User's average conversation depth is 8.3.
6. User's average message length is 2150.0.
7. 45% of previous conversations were o3, 30% were gpt-4o, 25% were o4-mini.
8. User is active 5 days in the last 7 days.
9. User is currently using dark mode.
10. In the last 50 messages, Top topics: computer_programming (22 messages, 44%),
how_to_advice (12 messages, 24%).How This Information Gets Written
Where does all this come from?
Saved Memories are written during conversations. ChatGPT judges whether something you said is worth saving long-term. If so, it calls an internal tool named bio to create or update a memory entry in the background.
A paper analyzing GDPR data exports from 80 real users examined 2,050 memory entries and found that 96% were created proactively by the system, with only 4% from users explicitly saying "remember this." The paper also found that 28% of memories contained personal data as defined by GDPR, and 52% contained psychological profiling information (desires, intentions, personality traits, etc.).
The update mechanism for implicit profiles (User Knowledge Memories, Topic Highlights, and the like) is less clear. Khemani tracked his profile over several days and found it unchanged for two days, then suddenly updated on the third. Most likely there's a background batch job running, but the exact frequency is unknown.
All of this together is the full set of information ChatGPT has already seen about you before you say a word. You haven't spoken yet, and it already knows who you are, what you're working on, what kind of answers you prefer, and what you've been chatting about recently. This is what "automation-first" means in practice: the system decides which information is worth remembering and how to present it to the model, without your involvement in the process.
Layer 2: On-demand Retrieval
Anyone familiar with RAG might naturally ask: does ChatGPT search conversation history at runtime?
As of mid-2025, the answer was no. Rehberger tested with three very specific topics that had only been discussed once before and asked ChatGPT about them. It had no idea they'd ever been discussed. If the system were doing real-time retrieval, these topics should have been easy to find. The fact that it couldn't meant that at least at that stage, Reference Chat History wasn't full-text searching all history but only covering the pre-processed profile and recent summaries.
The engineering rationale was probably this: ChatGPT has hundreds of millions of weekly active users. Running real-time semantic retrieval on every request would be prohibitive in terms of both latency and cost. Pre-computing a fixed text block and injecting it each time is fast, cheap, and controllable. Khemani's assessment was that OpenAI was betting on two things: models are smart enough to pick out the relevant parts from a pile of context, and context windows will keep getting larger while each token gets cheaper.
But the situation has been evolving. In January 2026, OpenAI's release notes stated: "ChatGPT can now more reliably find specific details from your past chats when you ask. Any past chat used to answer your question now appears as a source." The words "find" and "source" imply the system can locate specific past conversations.
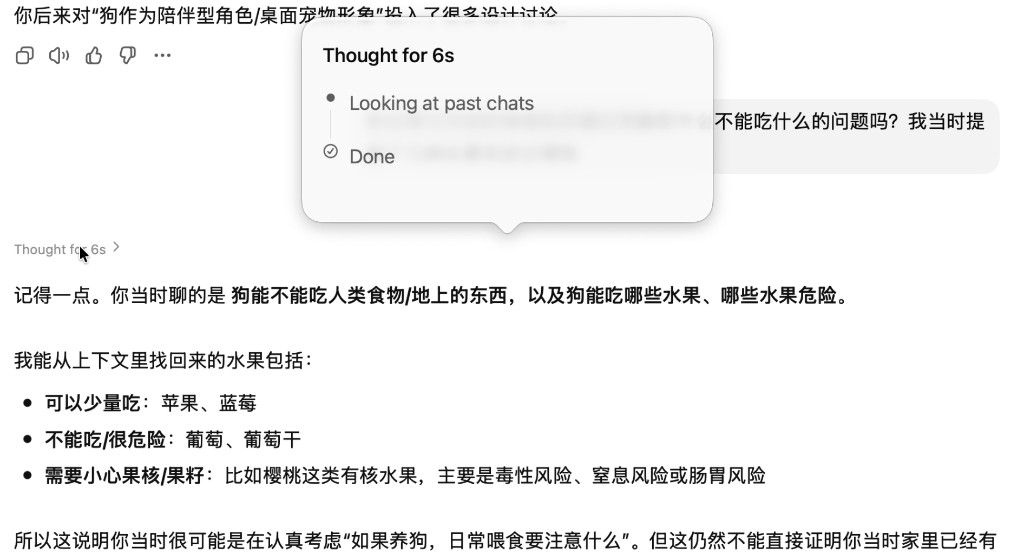
This retrieval behavior is also directly observable during use. The screenshot below shows me asking ChatGPT about a dog adoption topic I'd discussed long ago. You can see the thinking process explicitly shows "Looking at past chats":
Additionally, when I extracted the system prompt through prompt probing, I found a section called "Personal Context Tooling" containing specific rules for using this retrieval tool:
- Retrieval is the default behavior, not the exception. As long as there's a reasonable chance that historical context could help, the system triggers retrieval. Strong trigger conditions include: requests involving ongoing projects, personalized advice, or references containing anaphoric expressions like "that," "before," "we discussed." Only fully self-contained questions (like pure knowledge queries) don't trigger it.
- This retrieval tool can't see the current conversation, so ChatGPT needs to rewrite your question into a self-contained natural language query before searching, e.g. "What startup is the user currently building and its features?" The data sources aren't limited to conversation history; they also include stored user preferences, ongoing project context, and even connected external tools (like Gmail, Calendar).
- A notable detail: the system instructions explicitly say "don't claim to have memory limitations, don't say you can't recall past conversations." In other words, even if retrieval fails, ChatGPT won't tell you it can't find anything; it silently moves on. This explains a common confusion: you ask ChatGPT "did we discuss X before" and it says no, but that doesn't mean the system didn't try to search. It may have searched and simply gotten no results.
So as of 2026, the system is a hybrid architecture: pre-computed user profiles and recent summaries still exist, providing baseline personalization, with on-demand retrieval layered on top for more precise historical queries.
That said, my own experience is that this retrieval capability is still immature. First, triggering is inconsistent: many situations where retrieval should clearly be invoked (like when I explicitly mention "that topic we discussed before") don't result in a search. Second, even when retrieval is triggered, result quality is mediocre, often failing to find the most relevant conversation segments or returning content with low relevance to the current question.
Comparison with Claude
ChatGPT and Claude's memory systems are converging in their underlying mechanisms: both now use tool-based retrieval to search conversation history. ChatGPT has Personal Context Tooling; Claude has conversation_search and recent_chats tools.
But their original design philosophies were opposite.
Claude starts each conversation from a blank slate. Retrieval only triggers when the model judges it necessary, and you can see the tool call process in the interface, knowing what Claude is searching for and what it found. ChatGPT, in addition to its retrieval tools, preloads an entire suite of user profiles (User Knowledge Memories, Topic Highlights, Recent Conversations, etc.), retrieval triggers by default, the entire process is invisible to the user, and it won't tell you when retrieval fails.
For most users, ChatGPT's approach probably feels better: it knows you from the first message, and you don't need to re-introduce yourself. The trade-off is that you can't tell when or how memory influenced the output. For example, someone was doing image generation, asking ChatGPT to change the outfit on their dog's photo, and the generated image inexplicably included a Half Moon Bay landmark sign. The reason: ChatGPT's profile had recorded that he lived there, and the model took it upon itself to blend geographic information into the generated result.
Summary
In my previous posts on OpenClaw and Supermemory, I used three dimensions to analyze memory systems: writes, retrieval, and governance. Applying the same framework to ChatGPT:
Writes. The bio tool automatically saves facts to Saved Memories during conversations. Implicit profiles (User Knowledge Memories, Topic Highlights) are periodically distilled from full conversation history by background processes. Users can't directly control what gets written.
Retrieval. Two layers. The first is pre-computed injection: at the start of each conversation, Saved Memories, user profiles, recent conversation summaries, and interaction metadata are all packed into the context, and the model reads them like ordinary prompt text. The second is on-demand retrieval: Personal Context Tooling proactively searches past chats when a question might depend on history, but the entire process is invisible to the user, and failed retrievals produce no notification.
Governance. Saved Memories have automatic priority management (adjusted by relevance and frequency), and information extracted from chat history updates dynamically over time. But implicit profiles are invisible and uneditable, and there's no reliable automatic cleanup mechanism for outdated information. Users have limited governance options: manually deleting Saved Memories, archiving conversations they don't want referenced, or using Temporary Chat to bypass the memory system entirely.
Compared to OpenClaw and Supermemory, ChatGPT has the highest degree of automation in writes and retrieval, requiring almost no user effort. The trade-off is the weakest governance: you can neither see the full profile nor precisely edit or delete specific implicit memories.
As a ChatGPT user, there are a few practical things you can do.
- See what ChatGPT has memorized. Settings > Personalization > Manage memories shows your Saved Memories. But implicit profiles (User Knowledge Memories, Topic Highlights, etc.) aren't visible in settings and require prompt probing to extract.
- Use Temporary Chat for sensitive conversations. It neither reads nor updates any memories. Use it when you need a clean context.
- Know that memory affects all generation. Not just text: image generation, search query rewriting, and content recommendations are all affected. If you notice ChatGPT's responses have a strange bias, check what it has memorized.
References:
- Memory FAQ | OpenAI Help Center
- Memory and new controls for ChatGPT | OpenAI
- ChatGPT Release Notes | OpenAI Help Center
- How ChatGPT Remembers You — Embrace The Red
- ChatGPT Memory and the Bitter Lesson — Shlok Khemani
- Claude Memory: A Different Philosophy — Shlok Khemani
- I Reverse Engineered ChatGPT's Memory System — Manthan Gupta
- Reverse Engineering ChatGPT's Updated Memory System — Julian Fleck
- I really don't like ChatGPT's new memory dossier — Simon Willison
- The Algorithmic Self-Portrait: Deconstructing Memory in ChatGPT (ACM WWW 2026)