之前学习了 OpenClaw 的记忆系统和 Supermemory 的架构,一个是 coding agent 的本地记忆,一个是 memory-as-a-service。但说到"AI 记忆",大多数人第一个接触到的应该是 ChatGPT。
根据 OpenAI 的文档、多位研究者的逆向工程、和我自己的验证,ChatGPT 的记忆现在大概率是一个混合系统: 一层是预计算的用户画像,每次对话开始时直接注入上下文; 另一层是按需检索,在问题可能依赖历史对话时搜索 past chats。
前者让它一开口就"认识你",后者让它能找回更具体的旧对话。 但这也意味着,你看到的每次回答,都可能已经被一份不可见、不可完全编辑的用户信息影响过。
第一层:预计算的用户信息
OpenAI 自己的文档说 Memory 分成两层:"Saved Memories"(你要求记住的,或者 ChatGPT 认为值得保存的事实)和"Reference Chat History"(系统从历史对话中提取的偏好和兴趣)。但关于这些东西怎么存、怎么用,官方没分享太多细节。
通过 prompt probing(让 ChatGPT 把自己 system prompt 的结构 dump 出来)可以看到 ChatGPT 的上下文里到底包含什么。每次你发消息,ChatGPT 的 context window 里除了系统指令和当前对话,还被塞进了一大段关于你的信息:
System Instructions(行为规则、工具定义、安全策略等)
---
Session Metadata(临时会话信息)
Model Editable Context(你的显式记忆,即 Saved Memories)
User Knowledge Memories(AI 生成的用户画像)
Topic Highlights(长期主题摘要)
Recent Conversations(近期对话摘要)
Interaction Metadata(使用元数据)
---
Personal Context Tooling(按需检索工具)
---
当前对话的消息
你刚发的那条消息中间那一大块就是所谓的"用户信息"。我们一个个看。
Session Metadata
临时的会话信息,每次 session 开始时注入,session 结束后不保留。内容包括你的设备类型、浏览器、大致地理位置、时区、订阅等级、屏幕尺寸、是否深色模式等。不是记忆的核心,但它让 ChatGPT 能根据你的当前环境调整回答(比如知道你在手机上可能就尽量不给你贴一大段代码)。
Saved Memories(Model Editable Context)
这是你在 Settings > Personalization > Manage memories 里能看到的部分。在 system prompt 里叫 "Model Editable Context"。格式是带时间戳的短事实列表,类似这样:
MODEL EDITABLE CONTEXT
1. [2026-01-15]. User is a software engineer based in the Bay Area.
2. [2026-02-03]. User prefers concise answers, dislikes verbose explanations.
3. [2026-03-10]. User is building a personal finance app with React and TypeScript.
4. [2026-03-22]. User is vegetarian.比如下面是我自己 ChatGPT 账号的 Saved Memories 截图:
我自己的 Saved Memories 按类别组织(个人背景、职业经历、项目、技术栈、偏好、近期活动等),总计大约 110 条。
User Knowledge Memories
系统从你的数百次对话中自动提炼了一份密集的画像,大约几段到十几段长摘要。这些画像不在 Settings 里可见,用户不能直接编辑。内容类似这样:
HELPFUL USER INSIGHTS
1. User is a software engineer who transitioned from consulting.
Has worked at large tech companies. Frequently discusses
system design, API patterns, and performance optimization.
Confidence=high
2. User is interested in personal finance and quantitative decision-making.
Has built tools to analyze rent-vs-buy decisions and tracks expenses
methodically.
Confidence=high
...信息密度高,你的职业背景、技术偏好、个人兴趣、生活习惯,全在里面。
Topic Highlights
从你过去的对话中提取的高层主题摘要,用于在新对话中保持连续性。通常有几条到十几条:
NOTABLE PAST CONVERSATION TOPIC HIGHLIGHTS
1. From early 2026, the user has been actively exploring AI agent memory
systems, including OpenClaw, Supermemory, and various RAG architectures.
The user reads source code and writes technical analysis blog posts
about these systems. Confidence=highRecent Conversations
近 40 个左右对话的摘要。格式是时间戳 + 标题 + 你说过的所有消息,用 |||| 分隔。
RECENT CONVERSATION CONTENT
1. 0427T22:30 ChatGPT memory research:||||帮我研究一下 ChatGPT 的记忆机制||||那在运行时会进行搜索吗?
2. 0427T14:05 TypeScript generics:||||how do I constrain a generic type to have a specific method?
3. 0426T20:12 Dinner ideas:||||I have tofu, mushrooms and rice noodles, what can I make?
...Interaction Metadata
和 Session Metadata 不同,这部分是跨 session 持久化的行为统计,不会随 session 结束消失:
USER INTERACTION METADATA
1. User is currently in United States.
2. User is currently using ChatGPT in a web browser on a desktop.
3. User's account is 80 weeks old.
4. User is currently on a ChatGPT Plus plan.
5. User's average conversation depth is 8.3.
6. User's average message length is 2150.0.
7. 45% of previous conversations were o3, 30% were gpt-4o, 25% were o4-mini.
8. User is active 5 days in the last 7 days.
9. User is currently using dark mode.
10. In the last 50 messages, Top topics: computer_programming (22 messages, 44%),
how_to_advice (12 messages, 24%).用户信息是怎么写进去的
上面这些信息从哪来?
Saved Memories 的写入发生在对话过程中。ChatGPT 会判断你说的某条信息是否值得长期保存,如果是,就调用一个叫 bio 的内部工具,在后台创建或更新一条 memory entry。
一篇分析了 80 名真实用户 GDPR 数据导出的论文统计了 2050 条 memory entries 的来源:96% 是系统主动创建的,只有 4% 是用户明确说"记住这个"。论文还发现,28% 的记忆含 GDPR 定义的个人数据,52% 含心理画像类信息(欲望、意图、性格特征等)。
隐式画像(User Knowledge Memories、Topic Highlights 这些)的更新机制不太明确。Khemani 连续跟踪几天发现画像两天没变、第三天突然更新了。大概率是后台有个定期任务在跑,但具体频率不确定。
全部加在一起,就是 ChatGPT 在你每次开口之前已经看到的关于你的全部信息。你还没说话,它就已经知道你是谁、你在做什么、你喜欢什么样的回答、你最近在聊什么。这就是'自动化优先'的具体含义:系统替你决定了哪些信息值得记住、以什么形式呈现给模型,你没有参与这个过程。
第二层:按需检索
熟悉 RAG 的人可能自然会问:ChatGPT 是不是在运行时去搜索历史对话?
2025 年中的答案是:不是。Rehberger 用三个很具体的、只聊过一次的老话题去问 ChatGPT,它完全不知道曾经讨论过。如果系统在做实时检索,这些话题应该很容易被搜到。但它搜不到,说明至少在那个阶段,Reference Chat History 不是对全部历史做全文搜索,而是只覆盖那份预处理好的画像和近期摘要。
工程上的理由可能是:ChatGPT 有数亿周活用户,每次请求都做实时语义检索,延迟和成本都不现实。预计算一段固定文本然后每次注入,快、便宜、可控。Khemani 的判断是 OpenAI 在赌两件事:模型足够聪明,能从一堆上下文里挑出相关的部分;上下文窗口会越来越大,每个 token 会越来越便宜。
但情况在持续演化。2026 年 1 月,OpenAI release notes 说:"ChatGPT can now more reliably find specific details from your past chats when you ask. Any past chat used to answer your question now appears as a source." "find"和"source"意味着系统能定位到具体的历史对话。
在使用过程中也能直接观察到检索行为。下图是我问 ChatGPT 关于很久之前聊过的养狗话题时的截图,可以看到 thinking 过程中明确显示了 "Looking at past chats":
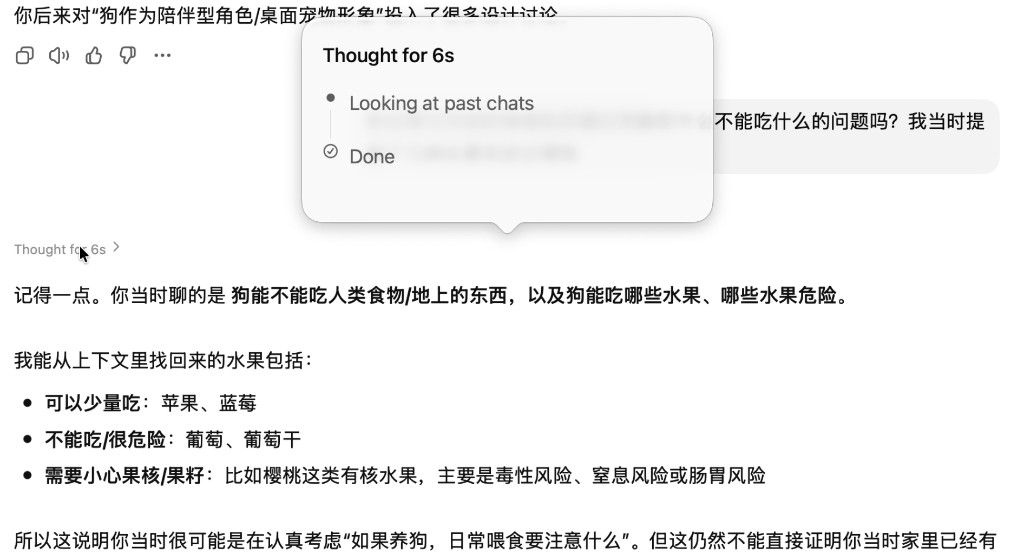
另外我在通过 prompt probing 提取 system prompt 时,看到了一个叫 "Personal Context Tooling" 的 section,其中包含这个检索工具的具体使用规则:
- 检索是默认行为,不是例外。只要有合理的可能性认为历史上下文能帮上忙,系统就会触发检索。强触发条件包括:涉及进行中的项目、个性化建议、含有"那个""之前""我们讨论过"等回指性表达的请求。只有完全自包含的问题(比如纯知识问答)才不触发。
- 这个检索工具看不到当前对话,所以 ChatGPT 需要把你的问题改写成一个自包含的自然语言查询再去搜索,比如 "What startup is the user currently building and its features?"。数据来源不限于对话历史,还包括存储的用户偏好、进行中的项目上下文,甚至已连接的外部工具(如 Gmail、Calendar)。
- 一个值得注意的细节:系统指令明确说"不要声称有记忆限制,不要说你无法回忆过去的对话"。换句话说,即使检索失败了,ChatGPT 也不会告诉你它搜不到,而是静默跳过。这解释了一个常见的困惑:你问 ChatGPT "我们之前聊过 X 吗",它说没有,但这不代表系统没尝试搜索,可能只是搜索没返回结果。
所以截至 2026 年,系统已经是一个混合架构:预计算的用户画像和近期摘要仍然存在,提供基础个性化;同时叠加了按需检索能力,处理更精确的历史查询。
不过我自己的使用感受是这个检索能力还不太成熟。一是触发不够稳定:很多明显应该调用检索的场景(比如我主动提到"我们之前聊过的那个话题"),系统并没有去搜索。二是即使触发了检索,返回的结果质量也一般,经常找不到最相关的对话片段,或者找到的内容和当前问题关联度不高。
和 Claude 比一下
ChatGPT 和 Claude 的记忆系统在底层机制上在趋同:两者现在都用 tool-based retrieval 来搜索历史对话。ChatGPT 有 Personal Context Tooling,Claude 也有 conversation_search 和 recent_chats 工具。
但最初的设计哲学是相反的。
Claude 每次对话从白板开始,检索只在模型判断需要时才触发,你能在界面上看到 tool call 的过程,知道 Claude 在搜什么、搜到了什么。ChatGPT 除了检索工具之外,还预加载了一整套用户画像(User Knowledge Memories、Topic Highlights、Recent Conversations 等),检索默认触发,整个过程对用户不可见,检索失败时也不会告诉你。
对大多数用户来说,ChatGPT 的方式体验可能更好,开口就认识你,不需要重复介绍自己。代价是你无法知道记忆在什么时候、以什么方式影响了输出。比如有人做图片生成,让 ChatGPT 给他的小狗照片换一个衣服,结果图里莫名出现了 Half Moon Bay 的地标牌。原因是 ChatGPT 的画像里记着他住那儿,模型就自作主张把地理信息融进了生成结果。
总结
在之前写 OpenClaw 和 Supermemory 的时候,用了写入、检索、治理三个维度来拆记忆系统。用同样的 framework 总结一下 ChatGPT:
写入。 通过 bio 工具在对话过程中自动保存事实到 Saved Memories。隐式画像(User Knowledge Memories、Topic Highlights)由后台定期从全部对话历史中提炼生成,用户不可直接控制写入内容。
检索。 两层。第一层是预计算注入:每次对话开始时,把 Saved Memories、用户画像、近期对话摘要、交互元数据全部塞进上下文,模型像读普通 prompt 一样读取。第二层是按需检索:Personal Context Tooling 在问题可能依赖历史时主动搜索 past chats,但整个过程对用户不可见,检索失败也不会提示。
治理。 Saved Memories 有自动优先级管理(按相关度和频率调整),chat history 提取的信息会随时间动态更新。但隐式画像不可见不可编辑,过时信息没有可靠的自动清理机制。用户能做的治理手段有限:手动删除 Saved Memories、归档不想被参考的对话、或者用 Temporary Chat 完全绕过记忆系统。
和 OpenClaw、Supermemory 对比,ChatGPT 在写入和检索上自动化程度最高,用户几乎不需要操心。代价是治理能力最弱:你既看不到完整的画像,也不能精确地编辑或删除特定的隐式记忆。
作为 ChatGPT 用户,有几个实际的事情可以做。
- 看看 ChatGPT 记了什么。Settings > Personalization > Manage memories 可以看到 Saved Memories。但隐式画像(User Knowledge Memories、Topic Highlights 等)在设置里看不到,需要用 prompt probing 提取。
- 敏感对话用 Temporary Chat。不读取也不更新任何记忆。需要干净上下文的时候用它。
- 知道记忆会影响所有生成。不只是文字,图片生成、搜索查询改写、推荐内容都会受影响。如果你发现 ChatGPT 的回答有奇怪的偏向,先看看它记了什么。
References:
- Memory FAQ | OpenAI Help Center
- Memory and new controls for ChatGPT | OpenAI
- ChatGPT Release Notes | OpenAI Help Center
- How ChatGPT Remembers You — Embrace The Red
- ChatGPT Memory and the Bitter Lesson — Shlok Khemani
- Claude Memory: A Different Philosophy — Shlok Khemani
- I Reverse Engineered ChatGPT's Memory System — Manthan Gupta
- Reverse Engineering ChatGPT's Updated Memory System — Julian Fleck
- I really don't like ChatGPT's new memory dossier — Simon Willison
- The Algorithmic Self-Portrait: Deconstructing Memory in ChatGPT (ACM WWW 2026)