This post was originally written in Chinese and translated to English by Gemini 3.1 Pro. The original version is here.
Last week, I posted a note on Xiaohongshu (a popular Chinese social platform similar to Instagram/Pinterest) to promote a desktop pet app I built over the weekend: PawPal.
GitHub Repo | Xiaohongshu Note
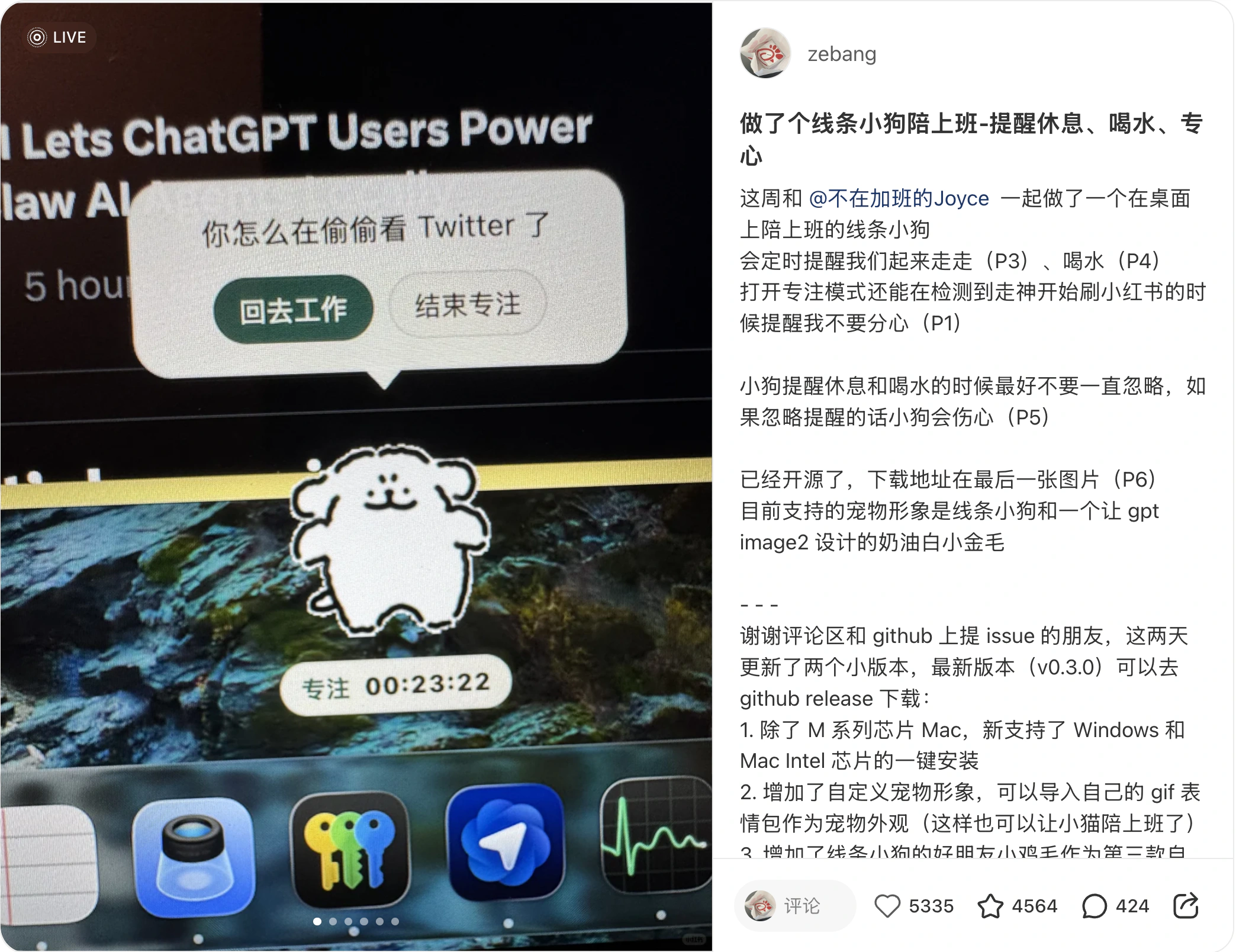
A week after publishing, the post received 60k views, 10k+ likes and saves, and brought in 300 GitHub stars and over 2,200 installation downloads.
I built this little toy not because I desperately needed a desktop pet, but to run an experiment on a new development workflow.
With Coding Agents getting stronger, building a complete app from scratch to MVP only takes a weekend. When "building the thing" is no longer the bottleneck, the real bottleneck becomes: once it's built, how do you find users?
So I wanted to try shifting the focus from "how to build a product" to "how to get the product seen." Instead of asking "what do I want to build," I asked "what goes viral easily on social platforms?" I wanted to find the demand on Xiaohongshu, reverse-engineer the product, and then throw it back onto Xiaohongshu for distribution.
I named this process Distribution-Driven Development (DDD).
This post is a teardown of this experiment one week in. I want to talk about whether this "backwards" workflow actually works, and exactly how many real software users a 60k-view social media post can convert.
1. How to Find a High-Potential Product Direction
The starting point of this experiment wasn't "what product do I want to build," but "what product is easy to spread and acquire users for." So my core metrics were twofold: Xiaohongshu views/interactions (measuring distribution) and GitHub release downloads (measuring actual conversion).
Reverse-Engineering the Product from Content
Since the focus is distribution, the first question when choosing a product direction is: Can I write a highly shareable piece of content around this product?
The most basic requirement for a viral Xiaohongshu post is that users stop scrolling the moment they see the cover. MediaStorm 影视飓风 shared their methodology for choosing video topics: the starting point isn't the video content, but the title and thumbnail.
The same logic applies. The first touchpoint between my product and the user is the post's cover image. If a product's function can't be intuitively demonstrated in a single screenshot, or if it takes a paragraph to explain what it does, the friction for spreading it on social media will be massive. So my first filter for a product direction was: Can this product's demo screenshot be directly used as a cover image that people instantly understand and want to click?
At the same time, the target audience can't be too narrow. "Reminding you to rest, drink water, and not get distracted" is a universal pain point for students and office workers. You don't need any domain knowledge to understand its value. But if I built a niche developer CLI tool, the audience would be much narrower, making social media distribution much harder.
A desktop pet running around on your screen naturally meets these criteria: it's highly visual, instantly understandable, easy to explain, and has a broad audience. This was the core reason I chose this direction.
Validating with "Low-Follower Viral Posts"
Another way to validate content potential is to search related keywords and look for "low-follower viral posts."
When a massive influencer's post goes viral, it might just be due to their follower base. But if an ordinary account that normally gets a dozen likes suddenly drops a post with thousands of likes, it means the content itself precisely hit a user need.
I found a few very strong signals:
For example, @大肥橘卡卡, who usually just posts pictures of their cat (getting ~10 likes), posted about "turning my cat into a desktop pet to play with at work," which got 5,000+ likes and 2,000+ saves.
Another user, @桌宠墩墩, who normally posts restaurant reviews (~10 likes each), posted "I made a desktop pet to supervise me from getting distracted," getting 5,000+ likes and 3,000+ saves.
The key is that the products in these two posts were just half-baked personal projects, but the comment sections were flooded with people begging for a download link. The demand was validated, but the supply didn't exist yet.
How to Write a Traffic-Driving Post
The product is the content. This was my biggest takeaway from the experiment.
Traditional product launches involve building the product first, then figuring out how to promote it.
But in the DDD model, everything is reversed: you have to figure out how to write the social media post first, and then design the product. The product itself exists to serve the content.
Besides being "highly visual," I found two highly effective shortcuts when writing the post.
One is leveraging existing IP. Initially, my wife and I used AI to generate a cute cream-colored golden retriever to use as the default pet. But when preparing the post, I realized that Line Puppy Maltese is a default, highly recognizable IP on the platform.
So I made a last-minute decision to replace all the screenshots in the post with Line Puppy Maltese (strictly for free, open-source, non-commercial use, of course). When people scroll past a familiar meme character, there's zero cognitive load and natural affinity.
The other shortcut is speaking the platform's language. My post title was "Made a Line Puppy Maltese to keep me company at work - reminds me to rest, drink water, and focus." In the body, I wrote "...when it detects my mind wandering and I start scrolling Xiaohongshu, it reminds me not to get distracted..." This self-deprecating "corporate drone" tone works much better than a dry "A cross-platform desktop reminder tool built with Electron."
Before publishing this post, my account had exactly 86 followers. I'm not a KOL, and I had no follower base. Yet this post got 462k impressions, 60k views, and 5,340 likes.
Xiaohongshu's content algorithm is essential here. On platforms heavily reliant on follower distribution like Twitter or WeChat, an 86-follower account's post would likely sink like a stone. This algorithmic mechanism is the infrastructure that makes DDD viable on Xiaohongshu.
2. The Conversion Funnel: Actual Data
This is the data I wanted to see most: exactly how many actual app users can a 60k-view social media post convert?
The full funnel (Date range: 2026-05-01 to 2026-05-11):
| Stage | Count | Data Source |
|---|---|---|
| Xiaohongshu Impressions | 462,000 | Creator Center |
| Xiaohongshu Views | 60,000 | Creator Center |
| Xiaohongshu Interactions (Like+Save+Share+Comment) | 14,000+ | Note Management |
| Xiaohongshu Profile Visitors | 3,041 | Creator Center |
| GitHub Unique Visitors | 2,086 | GitHub Traffic |
| GitHub Release Page Visitors | 993 | GitHub Traffic |
| Installer Downloads | 2,202 | GitHub Releases API |
| GitHub Stars | 310 | GitHub |
| Xiaohongshu New Followers | 170 | Creator Center |
| Personal Website Visitors | 213 | Vercel Analytics |
A few stages worth expanding on:
High Interaction Quality
The normal interaction structure on Xiaohongshu is that likes far outnumber saves and shares. This post was different:
| Interaction Type | Count | % of Views |
|---|---|---|
| Likes | 5,340 | 8.93% |
| Saves | 4,568 | 7.64% |
| Shares | 3,692 | 6.17% |
| Comments | 418 | 0.70% |
| Total Interactions / Views | 23.44% |
Saves were 85% of likes, and shares were 69% of likes. This isn't the "cute, drop a like and leave" consumer interaction. This is "I need to save this to use later" and "I need to send this to my coworker" utility interaction.
I think this is directly related to the product choice. A desktop pet reminding you to rest and drink water isn't purely aesthetic consumption; it solves a real, universal pain point. Users save it because they genuinely intend to come back and download it, and they share it because they think their friends need it too.
Xiaohongshu to GitHub: 95% of "Expected" Conversions Eaten by Friction
Out of 460k impressions and 60k views, only about 1,500 people actually made it to GitHub (deduced after filtering out t.co and other sources). The conversion rate from impression to GitHub was just 0.3%.
It's hard to judge this number in isolation, so we need a benchmark.
Coincidentally, I have a control group. Two days after the GitHub launch, a Twitter influencer with 100k followers @geekbb organically retweeted PawPal, translating my GitHub intro into a tweet. That tweet got 12,300 views (64 likes, 8 retweets, 3 comments) and brought in 215 GitHub visitors.
Looking at content appeal, using interaction rate (interactions / impressions) as a proxy:
| Xiaohongshu | ||
|---|---|---|
| Impressions / Views | 462,000 | 12,300 |
| Interactions (Like+Save+RT+Comment) | 14,018 | 75 |
| Interaction Rate (Interactions / Impressions) | 3.0% | 0.6% |
Xiaohongshu's interaction rate was 5x that of Twitter. The Xiaohongshu audience bought into the content much more.
But looking at GitHub conversion rates, the tables turned:
| Xiaohongshu | ||
|---|---|---|
| GitHub Unique Visitors | ~1,500 (deduced) | 215 (t.co actual) |
| Impression → GitHub Conversion Rate | 0.3% | 1.75% |
Twitter's conversion rate was 6x that of Xiaohongshu.
If content appeal were the primary variable, Xiaohongshu's 5x interaction rate should correspond to a ~5x GitHub conversion rate, or ~8%. The actual rate was 0.3%. Roughly 95% of the "expected" conversions evaporated in the middle steps.
Where did they go? The most direct reason is that Xiaohongshu doesn't allow external links in posts. I had to leave the GitHub URL in a pinned comment and the last image of the post. To download it, a user has to exit Xiaohongshu, open a browser, and manually type or search the URL. Each additional step bleeds users. For Twitter users, the link is right there in the tweet—one click and you're on GitHub.
Another reason is likely the user persona. People following tech influencers on Twitter include many developers who have zero friction navigating a GitHub link. But when Xiaohongshu pushes the post to office workers, many probably don't even know what GitHub is, let alone how to find an installer on a Release page.
Regardless, from a product distribution perspective, this is the "structural loss" you have to accept when using Xiaohongshu as a top-of-funnel channel.
Traffic Spillover
PawPal also brought some spillover traffic. While not critical, it's a useful reference. 3,041 people visited my Xiaohongshu profile, resulting in 170 new followers. 213 people visited my personal website (zebang.li) in 10 days, a 127% increase from the previous period.
3. Engineering Learnings
Windows Demand Was Severely Underestimated
The first version of PawPal only supported Mac ARM. Before launching, I figured a Mac version was enough for an MVP test.
The comment section quickly humbled me. The comments were flooded with "Is there a Windows version?" Some people even pulled the source code to run it on Windows themselves, coming to the comments to report bugs and confirm the installation process. The very next day, I scrambled to add a Windows installer.
If you look at total downloads, Windows accounts for about 40%. But that data is polluted—the first two versions didn't even have a Windows build. If we exclude the first two versions and only look at releases where both Mac and Windows were offered simultaneously, the true download distribution is:
| Platform | Downloads | Percentage |
|---|---|---|
| Windows | 1045 | 55% |
| macOS ARM | 750 | 40% |
| macOS Intel | 106 | 5% |
Windows is the absolute majority.
Looking back, Xiaohongshu's user base is structurally completely different from Hacker News or the Twitter developer bubble. In the latter, Mac is dominant, but on Xiaohongshu, Windows has a much higher share.
The lesson: Your distribution channel determines your user persona, and your user persona dictates your product decisions. Because there was no Windows version initially, many Windows users in the first wave of traffic who were interested couldn't download it and churned. Those people likely didn't come back when the Windows version launched the next day.
Electron: Nobody Cares
PawPal is built with Electron. Before building it, I hesitated: for a tiny desktop tool, an Electron app means a 140MB installer. Will users complain that it's bloated and resource-heavy? Should I spend time wrestling with Tauri to bring the size down?
The reality: across 400+ comments and a dozen GitHub issues, not a single person mentioned Electron, and no one complained about file size or memory usage. Users only cared about whether the dog looked cute, if there was a Windows version, and if they could import custom pets.
Recently, Claude released its desktop app, which is also an Electron wrapper. A bunch of developers on Hacker News complained about it. But an Anthropic engineer replied very pragmatically: the team is familiar with it, they can share code with the web version, and AI writes Electron code very well. For PawPal, it's the exact same story. I'm most familiar with the Web stack; using Electron, I could get an MVP running in a weekend. If I had stubbornly tried to fight with Rust bindings in Tauri just for a smaller file size, this weekend project would have likely been abandoned.
The bigger realization is the massive mismatch between what developers spend time agonizing over (tech stack) and what actual users care about. We debate Electron vs. Tauri vs. Native, arguing over a 50MB memory difference. But real users don't care. They care if the product is useful, feature-complete, and looks good.
This isn't to say tech stacks don't matter in the Agentic Coding era. For large-scale products, high-performance scenarios, and long-term team projects, the tech stack is critical. But for a small product meant to quickly validate demand, choosing what you're most familiar with—and what your coding agent writes most fluently—is entirely sufficient.
Comment-Driven Iteration
In the week after the post went live, I pushed 6 releases:
| Date | Version | What Changed | Trigger Source |
|---|---|---|---|
| 5/1 | v0.1.0 | Initial release, Mac ARM only | |
| 5/1 | v0.1.1 | Bug fix | Self-testing |
| 5/2 | v0.1.2 | Added Windows & Mac Intel support | Comments + User testing |
| 5/3 | v0.1.3 | Fixed dragging bug | Comment reports |
| 5/6 | v0.2.0 | Added Line Puppy Golden Retriever, launch at login | Issue #15 + Comments |
| 5/7 | v0.3.0 | Custom GIF import | Comment requests |
Every single release was a direct response to feedback from comments or GitHub issues. Xiaohongshu is essentially a free, real-time, highly active product backlog. You don't need to send out surveys; what users want is written right there in the comments.
This iteration speed—seeing a feature request in the morning and pushing a new release in the afternoon—used to be hard to imagine. But with Agentic Coding tools, the distance from requirement to code has been dramatically shortened. This is the foundation that makes DDD work: if a feature takes a week to ship, the hype on Xiaohongshu would have already gone cold.
Epilogue
Across the entire experiment, I invested about 20 hours (writing the MVP, iterating, writing the post) and spent $0 on promotion. In return, I got over 2,000 downloads, 400k impressions, and 300+ GitHub Stars.
The core steps of DDD can be summarized as:
- Reverse-engineer the product from content: First ask, "Can I write viral content around this product?" then ask, "Is this product worth building?" Specifically, can the product's demo screenshot be used as an instantly understandable social media cover? Is the audience broad enough?
- Validate with low-follower viral posts: Search target keywords to find high-interaction posts from low-follower accounts to validate the strength of the demand.
- Rapid development: Keep the MVP under three days to shorten the window between demand discovery and launch.
- Iteration loop: After the post goes live, use the comment section and GitHub issues as a real-time backlog for high-frequency iteration.
This methodology has clear limitations. It only works for visual, instantly understandable products with broad appeal. Niche tools, API services, and B2B SaaS have no natural content vehicle on these platforms. It requires rapid development capabilities (not suited for products with complex launch readiness). And it hasn't solved the monetization problem—people willing to download doesn't mean they're willing to pay.
But as an indie developer, or just someone with a fun idea who wants the fastest answer to "does anyone actually want this?", this method is absolutely worth trying. Plus, directly facing users and responding to real needs with code in real-time is pretty satisfying, honestly.